スーパーコンピュータ・システムSX-5/128M8の
フェアシェア・スケジューラによる運用(2002年度版)
東田 学(大阪大学サイバーメディアセンター 応用情報システム研究部門)
2001年1月5日より運用を開始したスーパーコンピュータ・システムSX-5/128M8は、導入後2年を経過し3年目をえた。
本システムは、Linpackベンチマークにてベクトル型スーパーコンピュータとしては初めて1TFLOPSをえる実効性能(1,192GFLOPS)を達成した画期的なシステムである。しかし、本年、本システムと同様のアーキテクチャを持つ地球シミュレータ(http://www.es.jamstec.go.jp/)が稼働し、Linpackベンチマークにて35.86TFLOPSという桁違いのベンチマーク性能を達成した。これは、米国にとってスプートニクショック以来の技術的屈辱と例えられる飛び抜けた性能であり、本センターのシステムは絶対性能としては随分見劣りするものとなってしまった(なお、地球シミュレータは、実シミュレーションでも10TFLOPSをえる性能を実現しており、この分野におけるベクトル・アーキテクチャの有用性を実証している)。2002年11月付けの“TOP500SupercomputerList”(http://www.top500.org/)においても、低価格でベンチマーク性能を発揮しやすいPCクラスター・システム進の煽りを受け、昨年の12位から34位にまで後退している。
しかし、利用者の声を聞くと、本システムが提供している機能は、依然としてい評価を得ている。特に、128GBという今なお最大規模の共有メモリ型主記憶と、どのノードからも16本のファイバーチャネルで共有接続された8TBのグローバル・ファイルシステム(/sxshort)によって、大規模シミュレーションのデータ解析において、他のシステムにないユーティリティを提供している。実際、地球シミュレータで行なったシミュレーション結果の解析を本システムにて行なっているユーザは少なくない。
2003年2月現在、/sxshortの利用率は90%くまで飽和しつつあり、大規模シミュレーションが要求するデータ解析量の膨大さの一端を物っている。東北大学情報シナジーセンターに導入された2TFLOPSという論理ピーク性能のSX-7と比べても、この点において競争力を失ってはいないし、そのユーティリティにおいて、ますます価値をめているとえよう。
このように、本システムは、稼働開始直後から現在まで継続的に活発に利用されており、本センター設置分の6ノードの利用率(稼働時のユーザによるプロセッサ利用率)は、昨年同様、通年で75%をえている。しかし、残念なことに、昨年度と比して、演算効率(いわゆるFLOPS値)が低下傾向にある。これは、プログラムの並列化が促進された反面、並列化チューニングが十分でないことが原因と考えられる。次年度は、これまで以上に、広報と講習会などの教育活動を行いたい。
また、次年度7月下旬には、本システムでは初めてのシステム管理ソフトウェアの更新を行う計画である。特に、これまでERSによる分散型のリソース管理を行なってきた。これは、ハイパフォーマンス・コンピュータのシステム運用ソフトウェアとしては画期的なものであったが、一方で、ノードの負荷が高まった時にリソース管理システムの過負荷によってユーザの演算がストールするという障害要因となっていた。次年度は、システムソフトウェアの更新に伴って、新版のERSによる外集中型のコンベンショナルなリソース管理方式への移行を行なうことを計画している。
1.平成14年度のノード稼働状況の推移
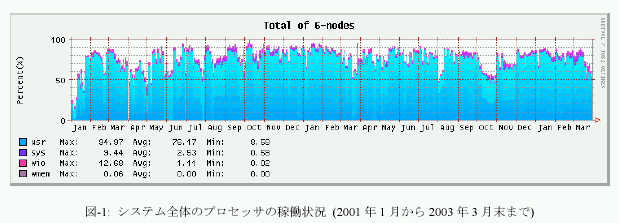
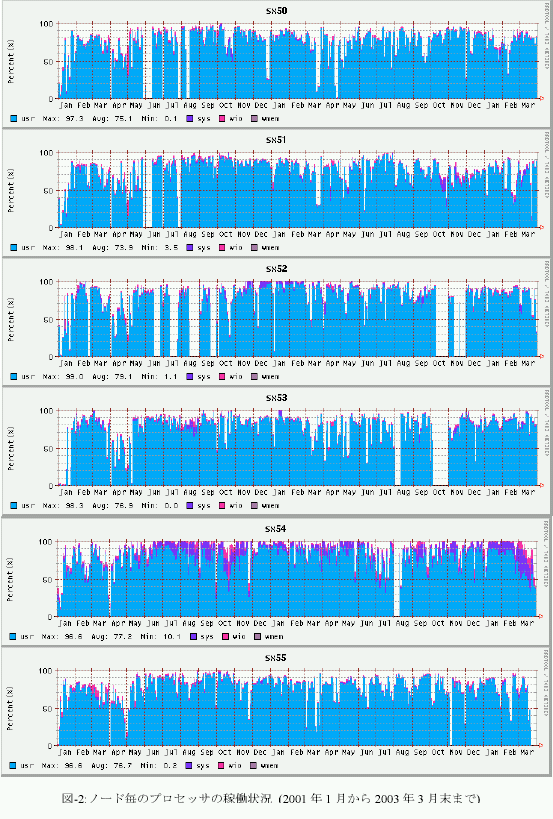
平成14年度のシステム全体のプロセッサの稼働状況を図-1に、ノード毎のプロセッサ稼働状況を図-2に示す。グラフの集期間は2001年1月から2003年3月末までである。これらのグラフは、システムの稼働状況を表示するUnixコマンドsarの出力値をグラフ化したもので、usr(ユーザがプロセッサを利用した割合)、sys(システムがプロセッサを利用した割合)、wio(I/O処理によってプロセッサを浪費した割合)、wmem(メモリ待ちによってプロセッサを浪費した割合)を積み上げたものである。それ以外の余白は、プロセッサがアイドルしていることを示す。
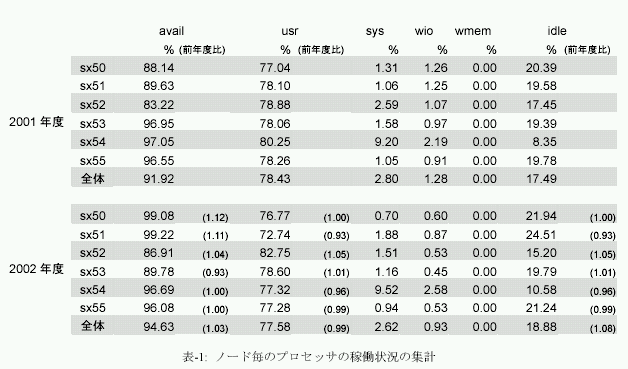
表-1は、それらの値の年度毎の平均値を集計したものである。表の内、availは、システムが稼働しsar情報の蓄積が行われた時間の割合であり、システムの源が入っていた時間の割合にほぼ等しい。以下の利用率は、この稼働時間に対する内訳である。
1.1 システムの稼働率
システム全体の稼働率は、2001年度が91.9%、2002年度が94.6%であり、漸増している。昨年度同様に節電を目的としたノード#2、#3の適宜停止措置を行なっているが(昨年度は#0、#1、#3にて節電調整を行った)、節電措置を行なっていないノードの稼働率は、最も高いノード#0が99.1%に達し、一年の内、停止したのは計画停時とハー ドウェア保守などによる4日未満と非常に安定していた。
システム全体の運用のために必要なERSやGFSなどのサーバ・プロセスを動作させている#4の稼働率であるが、昨年度97.1%、本年度96.7%とほぼ横ばいであった。停止時間は10日から12日と月一日以内に収まった。ハードウェアは十分、安定したサービスを提供し得たとえよう。
1.2 ユーザ利用率とアイドリング
システム全体のユーザ利用時間の割合であるが、昨年度が78.4%、本年度が77.6%であった。この値もほぼ横ばいであり、ノード毎の昨年度と本年度の利用率の変化も、それぞれ±数%の差に落ち着いている。しかし、後で詳細を分析するように、運用・利用の形態は大きく様変わりしている。にもかかわらず、ユーザ利用率が大きく変化しなかったことは、ERSとギャング・スケジューラによる運用という大きな枠組が変わらなかったことによるものと考えられる。逆にえば、この利用率で飽和している現状を変えるためには、ERSまたはギャング・スケジューラによる運用を変える必要があるということである。次年度には、オペレーティング・システムのバージョンアップとともに、ERSも新しい枠組を採用したものに入れ換える予定である。システムのアイドル時間であるが、昨年度が17.5%、本年度が18.9%であった。本システムはギャング・スケジューラによる並列プロセス管理を行なっており、並列プロセスが同期待ちなどでスピン・ウェイトしている空き時間を、他のプロセス処理に渡さない。これは、システム全体の利用率の向上よりも、ユーザのターン・アラウンド・タイム向上や、課金対象時間の最小化などの便宜を優先させているからである。
なお、ユーザ利用率77.6%というのは、すべてのジョブが16並列プロセスとして実行されていたと仮定すると、並列化率98.1%に相当する。逐次実行すると一時間かかるジョブのうち、並列化不可能な処理時間が70秒弱。16並列で処理すると、全体で5分弱となる。5分のうち1分強が15プロセッサがアイドルしていると思うと、けっこうな無駄とも思える。ただし、これは、通年の利用率であり、もちろん個々のジョブの並列化率はもっと高いことはうまでもない。後述するように、p1キューのジョブが減り、p4やp8キューのジョブが増えていること、p16キューのジョブは相変わらず相当数が実行されていることを考慮すると、ユーザ・プログラムの並列化が促進されていると考察できる。
なお、並列実行率98.1%のジョブをp4で実行した時の効率は94.5%、p8では88.3%、p16では77.8%、mpi32では62.9%、mpi64では45.5%と50%以下にまで落ちる。逆に、mpi64で75%の効率を得ようとすると、並列実行率を99.5%までチューニングする
必要がある。その要求が1,024プロセッサでは99.97%(全体で一時間かかる実行処理のうち逐次処理にされるのは1秒未満)にもなる。
なお、昨年度の本報告と若干数値が異なるが、昨年度は、運用中にsarコマンド表示して得られた値からグラフを作成していたが、本年度は、sarデータベースから直接利用率を積算し、集計精度を上げていることをお断りしておく。
1.3 システムによる利用率
システムによる負荷の推移も、ほぼ昨年度と同様であった。利用実績の積算、課金統計やネットワークファイルシステムサーバ、インタラクティブジョブの処理を担当している#4ノードのシステム負荷が高いのは昨年度と同様であり、その負荷率もほぼ同じである。次年度7月に予定しているオペレーティング・システムのバージョンアップでは、#4の負荷低減を目的とした構成変更を計画している。これは、ノード内を分割するリソースブロック機能の活用と、ERSバージョンアップによるERSサーバの外部化にて行なう。
なお、昨年度同様、メモリ待ちによるプロセッサ時間の浪費はほとんどみられなかった。これは、本システムがベクトル機として適切に運用および利用されていることを示している。
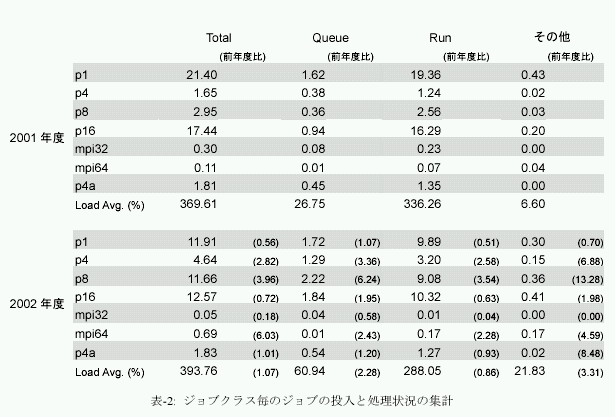
2.ジョブの投入と処理状況の推移
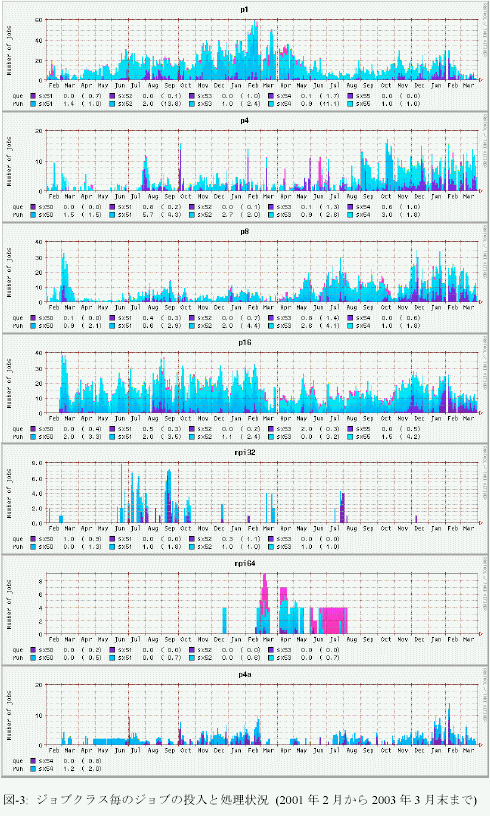
図-3に平成14年度のジョブクラス毎のジョブの投入と処理状況を示す。これは、一定時間毎のジョブ投入数と処理数の状況の推移をグラフ化したものである。グラフの集計期間は2001年2月から2003年3月末までである。表-2は、それらの値を年度毎に集計したものである。なお、表中のロードアベレージ(LoadAvg.)は、各キューの要求CPU数とジョブ数を掛け合わせ積算した値と、システムの総CPU数との比である。まず、ロードアベレージは370%から394%と前年度よりも7%高くなっており、本システムに対するユーザの処理要求が増していることを示している。一方、本年度、顕著に見られる傾向が、p1キューとp16キューのジョブ数の減少である。
p1キューに関しては、2001年度の同時処理件数が21.4ジョブから11.9ジョブへ46%減少した。その分に相当すると見られる量のジョブがp4キュー(前年度比2.8倍)とp8キュー(前年度比4.0倍)で増加しているので、これは並列化が促進されていると分析できる。
p16キューでのジョブ数の減少であるが、#4ノードは、様々な用途で雑務をこなしているため、実際の運用に際してp16を処理できるキューのスロットは5ノード分、すなわち5つしかない。2001年度は同時に16.3ジョブを実行していた。すなわち、ひとつのノードあたり多重度3で実行していたことになる。この多重度設定は大き過ぎ、実行ジョブのスワップのための負荷はさほどでもないものの、メモリ要求量が大きくなるにつれ、やはり無視できないものになった。また、ジョブ実行優先度がリアルタイムに変動することをうけ、一旦実行されたジョブが実行途中に優先度が低下し、ホールドされたままなかなか再開されず、ジョブ実行開始後の待ち時間が増加する傾向が現れてきた。
このような高実行多重度設定の弊害を解消するため、2002年度はジョブ実行多重度が2となることを目安に運用した。これを受け、キュー待ち状態にあるジョブが、通年では0.94から1.84とほぼ倍になった。これは特に問題となる増加ではないようにも見えるが、2002年末以降の繁忙期以来、キュー待ちは各キューで増加傾向にある。この傾向はグラフからも一目瞭然である。本的には、プロセッサ表-2:ジョブクラス毎のジョブの投入と処理状況の集数などシステム資源が増加しなければ解消しない問題ではあるが、運用の最適化により、ユーザ利用時間を高め、アイドル状態にあるプロセッサを減らすことで解消に勤めたい。
また、次の分析に見るように、ユーザ利用時間はほぼ一定割合で推移しているものの、単位時間当たりに処理している演算量、いわゆるFLOPS値は微妙な減少傾向にあり、システムのスループットを低下させているものと考えられる。ユーザに並列化率の向上を促す必要がある。
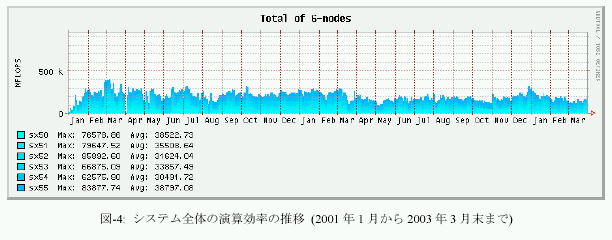
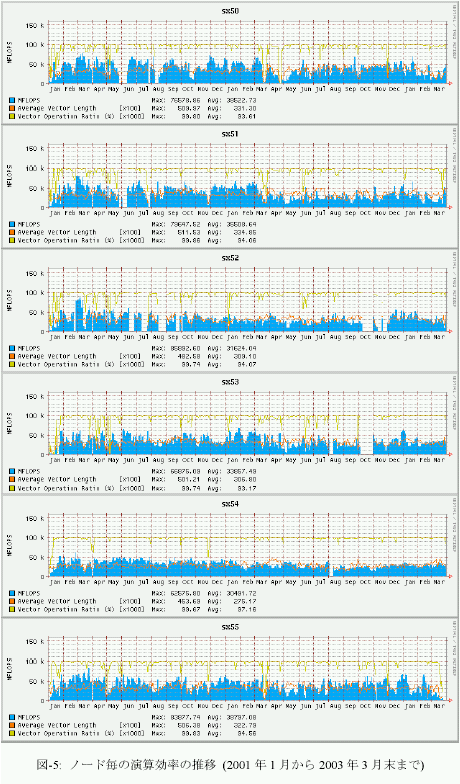
3.平成13年度の演算効率の推移
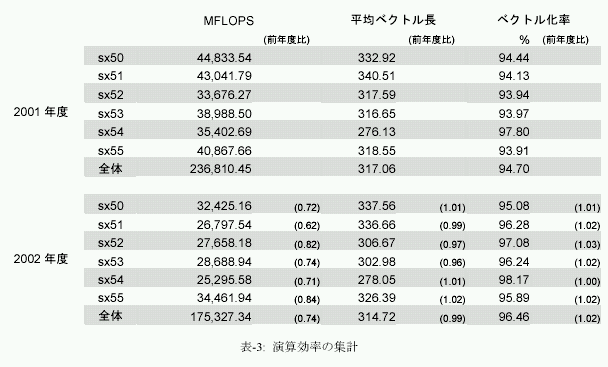
図-4にシステム全体の演算効率の推移を、図-5に、ノード毎の演算効率の推移を示す。グラフの集計期間は2001年1月から2003年3月末までである。表-3は、それぞれの値を年度毎に週集したものである。前節でも触れたように、単位時間当たりに処理している演算量、いわゆるFLOPS値が減少傾向にある。2001年度は、通年で236GFLOPSの処理をこなしていた。これはピーク性能960GFLOPSの25%に相当し、共同利用施に設置されているハイパフォーマンスコンピュータシステムとしては常に高い割合であると評価できた。しかし、2002年度は、前年度比では26%減少し、175GFLOPSとピーク性能比18%まで落ち込んでいる。これでも依然高い実効性能で利用されているとも評価できるが、前年度の実績があるだけに、手放しでは褒められない。
まず、ユーザ・プログラムのパフォーマンス・チューニングの指標となるベクトル化率や平均ベクトルの推移を観察すると、昨年度も本年度も大きな差はない。平均ベクトルは317から314と僅かに減少しているが、それが即演算効率に直結するような有意な差とは考えられない。ベクトル化率は94.7%から96.5%に微増している。
p16キューのジョブに関しては、実行多重度を3から2に下げたことにより、みかけの処理量は減っているが、ジョブ実行が途切れることはなく効率を落とすことはなく、逆に、より効率的に処理されるようになったはずである。
となると、p1キューを利用していたユーザが、並列化を行なってp4やp8キューを利用するようになったが、並列化チューニングが十分ではないと考えられる。先にも述べたように、4並列や8並列では、低い並列実行率でも、システムの利用率の落ち込みは少ないはずで、相対的にp16ジョブの実行の割合が減って、p8ジョブの実行の割合が増えればプロセッサ・アイドリングが少なくならなければならないのであるが、そうはなっていないことがチューニング不足を示唆している。
ユーザの利用状況を子細にモニタしていると、p8キューやp16キューであるにも関わらずシングル・スレッドで走っているジョブを時々発見する。その度、ユーザに連絡し、注意を換気しているが、現状のオペレーティング・システムでは、そのようなジョブを自動で発見する枠組が用意されておらず、システムの利用率が落ち込んでいる理由を逐一検証しながら、目の子作業でジョブを探しているのが現状である。並列ジョブは、常に並列実行されている訳でもなく、I/O処理時にはシングル・スレッドで動作しているなど、このようなトラッキング作業も並大抵ではないのである。
これに関しては、ベンダーと協力し、半自動的に低効率ジョブを発見できる枠組を構築する計画である。
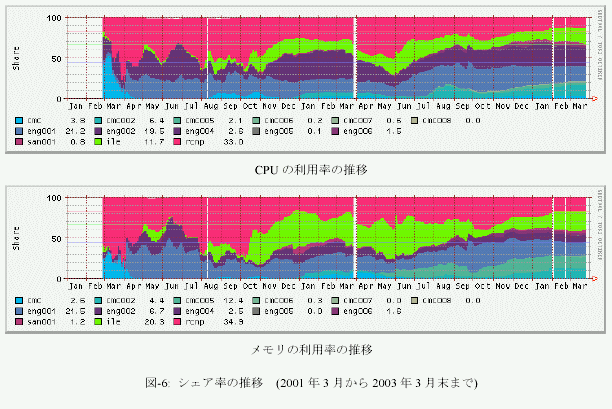
4.平成14年度のシェア率の推移
図-6は、フェアシェア定額制におけるシェア率の推移をグラフ化したものである。グラフの集計期間は2001年3月から2003年3月末までである。上段がCPUの利用率、下段がメモリの利用率の推移である。運用に際してはCPUの利用実績のみが考慮されている。本年度9月以降、半減期の延長を行った。また、並列ジョブへのインセンティブ付与の最適化によって、昨年度の大きな題であった出資額に応じたシェア率が達成されるようになったことを報告しておく。
ユーザ毎の利用率についても、昨年度は上位10ユーザによってシステム資源の7割から8割が利用CPUの利用率の推移されているような状況であったが、本年度は、上位10ユーザによってシステム資源の約半分、上位20から30ユーザによってシステム資源の7割から8割が利用されるという状況に分散化しつつある。
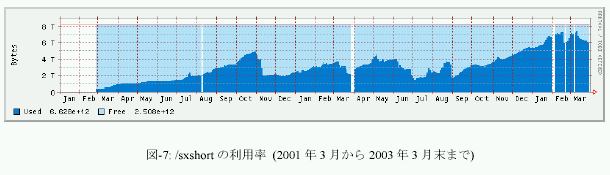
5.平成14年度のディスク利用率の推移
図-7は、/sxshortの利用率をグラフ化したモノである。グラフの集計期間は2001年3月から2003年3月末までである。8TBという大規模なフラット・パーティションを各ノードから16本のファイバーチャネル・インターフェイスによってストライピング接続した高性能作業領域/sxshortであるが、昨年度は40%前後の利用率で落ち着いていたものの、本年度10月以降利用率が漸増し、1月以降には、75%から90%、6TBから7TBが利用される状況にまで飽和しつつある。
次年度7月に計画しているオペレーティング・システムのバージョンアップ時に、このパーティションのクリアを予定しているので、データが溜っている利用者各位は、それまでにデータのをお願いしたい。
6.おわりに
フェアシェア定額制度を導入し2年余が経過した。本年からは、東北大学にてSX-7の運用が開始され、我々センターとしても、厳しい運用を迫られることとなっている。幸いにも、東北大学のシステム稼働後もジョブ投入数が減少することもなく、これまで同様の利用率で稼働している。次年度7月には、始めての大がかりなシステム構成変更を計画している。オペレーティング・システムのバージョンアップを行なうとともに、フェアシェア定額制度運用を支える基盤ソフトウェアであるERSのバージョンアップとキュー構成の変更も行なう。
これまでのERSは、利用実績データベースの管理をSX上で行なっていたため、恒常的に負荷のかかるアカウンティング処理を、その処理に向かないベクトルプロセッサで行なっていた。新しいERSは、外ホストでデータベース管理を行なうため、貴重なベクトルプロセッサ資源を浪費することがない。また、これまではNQSによる複数ノードへのジョブ投入はラウンドロビン・スケジューリングによって順次投入処理されていた。このアルゴリズムでは、ジョブ投入後、負荷が高いなど不適切なノードに投入されたジョブを他ノードへマイグレーション処理しなくてはならず、システムへの余分な負荷を与えていた。新しいNQSでは、ラウンドロビンを改め、ERSと連係し、適宜適切なノードへジョブ投入が行なわれる。
以上のように、運用の最適化を行うために、次年度7月下旬に2週間程の全面的なシステム停止を伴う保守作業を計画している。ユーザ各位のご理解とご協力をお願いしたい。また、それまでに/sxshortのデータ解析を終了させていただくよう重ねてお願いする次第である。