スーパーコンピュータ・システムSX-5/128M8の
フェアシェア・スケジューラによる運用(2003年度版)
東田 学 (サイバーメディアセンター 応用情報システム研究部門)
(manabu@cmc.osaka-u.ac.jp)
2001年1月5日より運用を開始したスーパーコンピュータ・システムSX-5/128M8は、導入後3年を経過し4年目を迎えた。(manabu@cmc.osaka-u.ac.jp)
本年度7月、導入以来、初めてシステム運用ソフトウェアのバージョンアップを行なった。オペレーティングシステムのメジャー・バージョンアップとともに、ジョブ実行管理システムであるNQS (Network Queuing System) およびERS (Enhanced Resource Scheduler) のメジャー・バージョンアップと、それに伴うシステムの物理的構成変更を含む大がかりな作業となった(なお、コンパイラの最新版への更新やバグフィックス等は適宜行なっている)。
前システムまでは本センター内のノード毎に遂行できた更新作業であるが、本システムでは、共同運用を行なっているレーザー核融合研究センター (ILE、現レーザーエネルギー学研究センター)と核物理研究センター (RCNP) に設置されているノードおよび、本センター内に設置されている6ノードに対して、ノード間の役割分担の依存関係を見極めながら、7月19日から8月5日の足掛け3週間、段階的な更新作業を行なうこととなった。事前に十分な検討を行なったつもりではあったが、何分我々にも未経験の大規模な更新作業であり、様々なトラブルが発生し、利用者各位に多大な迷惑をおかけしたことをこの場を借りてお詫びしたい。
本システムよりも遥かに大規模な地球シミュレータが安定稼働しており、また、本システム以降に導入された同規模の東北大学情報シナジーセンターのSX-7も安定して稼働している中、本システムのシステム運用ソフトウェア更新が困難を究めた理由は、フェアシェア・スケジューラによってマルチノードシステムを自律的に負荷分散運用するフレームワークを先進的に採り入れていることによる。
NQSは伝統的なバッチキュー管理システムであり、ERSはNQS APIを活用し自律的なフェアシェア型のジョブ・スケジューリングを行う。ユーザまたはユーザ・グループ毎に利用実績値を積算し、予め設定したシェア率を達成するように実行中のジョブの優先度を自律的に調整する。利用実績値は、設定した期間に半減するよう随時減算処理が行われる。これは、閑散期にユーザが投機的に先行利用することを促す効果がある。
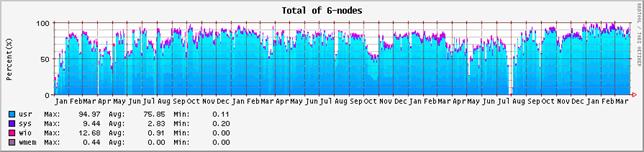
図-1:システム全体のプロセッサの稼動状況(2001年1月から2004年3月末まで)
このジョブ実行管理システムは、これまではスーパーコンピュータ本体で分散稼働していた。恒常的に負荷のかかるアカウンティング処理を各ノードで、また利用実績データベースの集計管理を#4ノードで行っており、そのような処理に向かないベクトルプロセッサを浪費していた。このような分散型の資源管理方式は革新的な取り組みではあったが、高性能コンピュータシステムにおいてはノードの負荷が高まった際に資源管理システムの過負荷によってサービスがストールするという障害要因となっていた。このため、システム運用ソフトウェアの更新に伴って、新たにフロントエンド・サーバを設け、外部集中管理型のコンベンショナルな資源管理方式への移行を行なうこととなった。
また、これまではNQSによる複数ノードへのジョブ投入はラウンドロビン・スケジューリングによって順次循環投入処理されていた。このアルゴリズムでは、ジョブ投入後、ERSによって負荷が高いなど不適切なノードに投入されたと判断したジョブを他ノードへ改めてマイグレーション処理しなくてはならず、システムへの余分な負荷を与えていた。新しいNQSでは、ラウンドロビンを改め、あらかじめERSの資源管理情報を参照し適宜適切なノードへジョブ投入が行なわれる。
更に昨今のグリッドウェアと親和性を持たせたのが本作業のもうひとつの成果である。例えば、新しいNQSは、グリッド・コンピューティングを意識してPOSIX準拠(POSIX.15およびIEEE1003.2d)となりデファクト・スタンダードであるPBSと操作性およびスクリプトの記述とも互換インターフェイスになった。
システム更新以降、様々なバグフィックスに追われながら、繁忙期を控えた11月までにはなんとか更新前の安定性を取り戻し、通年での利用率は前年度と同等の74%を維持した。改めて利用者各位の忍耐強いご協力に感謝するとともに、今回の更新作業が妥当なものであったことを強調したい。以下、詳細に検証を行う。
| avail % (前年度比) |
usr % (前年度比) |
sys % |
wio % |
wmem % |
idle % (前年度比) |
|||||
| 2001年度 | sx50 | 88.14 | 77.04 | 1.31 | 1.26 | 0.00 | 20.39 | |||
| sx51 | 89.63 | 78.10 | 1.06 | 1.25 | 0.00 | 19.58 | ||||
| sx52 | 83.22 | 78.88 | 2.59 | 1.07 | 0.00 | 17.45 | ||||
| sx53 | 96.95 | 78.06 | 1.58 | 0.97 | 0.00 | 19.39 | ||||
| sx54 | 97.05 | 80.25 | 9.20 | 2.19 | 0.00 | 8.35 | ||||
| sx55 | 96.55 | 78.26 | 1.05 | 0.91 | 0.00 | 19.78 | ||||
| 全体 | 91.92 | 78.43 | 2.80 | 1.28 | 0.00 | 17.49 | ||||
| 2002年度 | sx50 | 99.08 (1.12) | 76.77 (1.00) | 0.70 | 0.60 | 0.00 | 21.94 (1.00) | |||
| sx51 | 99.22 (1.11) | 72.74 (0.93) | 1.88 | 0.87 | 0.00 | 24.51 (0.93) | ||||
| sx52 | 86.91 (1.04) | 82.75 (1.05) | 1.51 | 0.53 | 0.00 | 15.20 (1.05) | ||||
| sx53 | 89.78 (0.93) | 78.60 (1.01) | 1.16 | 0.45 | 0.00 | 19.79 (1.01) | ||||
| sx54 | 96.69 (1.00) | 77.32 (0.96) | 9.52 | 2.58 | 0.00 | 10.58 (0.96) | ||||
| sx55 | 96.08 (1.00) | 77.28 (0.99) | 0.94 | 0.53 | 0.00 | 21.24 (0.99) | ||||
| 全体 | 94.63 (1.03) | 77.58 (0.99) | 2.62 | 0.93 | 0.00 | 18.88 (1.08) | ||||
| 2003年度 | sx50 | 96.88 (0.98) | 71.85 (0.94) | 3.18 | 0.13 | 0.00 | 24.84 (1.13) | |||
| sx51 | 98.12 (0.99) | 70.18 (0.96) | 2.25 | 0.18 | 0.00 | 27.39 (1.12) | ||||
| sx52 | 91.39 (1.05) | 72.57 (0.88) | 2.85 | 0.15 | 0.00 | 24.43 (1.61) | ||||
| sx53 | 97.80 (1.09) | 77.87 (0.99) | 3.53 | 0.13 | 0.00 | 18.47 (0.93) | ||||
| sx54 | 98.79 (1.02) | 76.04 (0.98) | 5.23 | 2.74 | 0.00 | 15.99 (1.51) | ||||
| sx55 | 94.29 (0.98) | 77.89 (1.01) | 3.07 | 0.75 | 0.00 | 18.78 (0.88) | ||||
| 全体 | 96.21 (1.02) | 74.40 (0.96) | 3.35 | 0.68 | 0.00 | 21.65 (1.15) | ||||
1. 2003年度のノード稼働状況の推移
2003年度のシステム全体のプロセッサの稼働状況を図-1に、ノード毎のプロセッサ稼働状況を図-2に示す。グラフの集計期間は2001年1月から2004年3月末までである。これらのグラフは、システムの稼働状況を表示するUnixコマンドsarの出力値をグラフ化したもので、usr(ユーザがプロセッサを利用した割合)、sys(システムがプロセッサを利用した割合)、wio(I/O処理によってプロセッサを浪費した割合)、wmem(メモリ待ちによってプロセッサを浪費した割合)の各表示項目を積み上げたものである。それ以外の余白は、プロセッサがアイドルしていることを示す。
表-1は、それらの値の年度毎の平均値を集計したものである。表の内、availは、システムが稼働しsar情報の蓄積が行われた時間の割合であり、システムの電源が入っていた時間の割合にほぼ等しい。利用率は、この稼働時間に対する内訳である。






図-2:ノード毎のプロセッサの稼動状況(2001年1月から2004年3月末まで)
1.1 システムの稼働率
システム全体の稼働率は、2001年度が91.9%、2002年度が94.6%、2003年度が96.2%であり、引き続き漸増している。バージョンアップ期間中も作業のため通電していたため、稼働率には悪影響を与えなかった。これまでと同様に、節電を目的としたノード#2、#5の適宜停止措置を行なっているが(昨年度は#2、#3にて、一昨年度は#0、#1、#3にて節電調整を行った)、節電措置を行なっていないノードの稼働率では、最も低いノード#0が96.9%であった。これは、一年の内12日未満であり、非常に安定していたといえよう。
システム全体の運用のために必要なERSやGFS (Global File System) などのサーバ・プロセスを動作させている#4の稼働率であるが、一昨年度97.1%、昨年度96.7%とほぼ横ばいであったが、本年度は98.8%まで向上した。停止時間は10日を超えていたものが5日未満まで安定し、停止したのは計画停電時とハードウェア保守などによる最小限に止まった。
初期不良による部品交換や調整作業も一段落し、ハードウェアは十分、安定したサービスを提供し得たと言えよう。
1.2 ユーザ利用率とアイドリング
システム全体のユーザ利用時間の割合であるが、一昨年度が78.4%、昨年度が77.6%、本年度が74.4%であった。7月24日から8月4日(ノードによっては5日)までのバージョンアップ期間はユーザ・サービスを停止しており、断続的な更新作業に伴う利用率の計上は伴ったものの、ほぼアイドル状態であった。この11日分または12日分の目減り(3%に相当)を考慮すれば、ユーザ利用率はほぼ横ばいであったと評価できよう。まず、バージョンアップに伴う運用状況の変化を考察すると、図-1、2のグラフを見れば明らかなように、バージョンアップ前の7月以前とバージョンアップ後の8月以降で際だった改善が見られる。前年同月比で比較すると、8月以降、0.72 倍(8月)、0.94倍(9月)、1.07倍(10月)、0.97倍(11月)、1.06倍(12月)、1.10倍(1月)、1.15倍(2月)、1.20倍(3月)というように、特に繁忙期の12月から2月にかけて利用率が著しく向上した。
なお、8、9月はバージョンアップに伴うトラブルシュートに追われ思うように利用率が上がらず、11、12月は#0、#1ノードにて非常に大規模な32並列ジョブが占有し、その期間中それぞれのノードで50%まで利用率が下がっている。そのような負要因にも関わらず、この運用結果が得られたことは、バージョンアップの正当性を示すデータとして評価されよう。また、各ノードにバランス良く負荷分散されており、資源管理ソフトウェアの効率が改善されたことを反映している。
システム全体のアイドル時間であるが、一昨年度が17.5%、昨年度が18.9%、本年度が21.65%であった。先に述べた更新期間中の3%分相当を考慮すれば、ほぼ過去の実績並みであった。
本システムはギャング・スケジューラによる並列プロセス管理を行なっており、並列プロセスが同期待ちなどでスピン・ウェイトしている空き時間を、他のプロセス処理に渡さない。これは、システム全体の利用率の向上よりも、ターン・アラウンド・タイム向上や、課金対象時間の最小化などのユーザの便宜を優先させているからである。
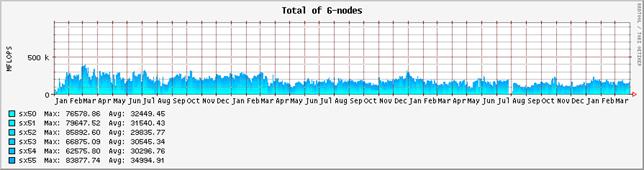
図-3:システム全体の演算効率の推移(2001年1月から2004年3月末まで)
1.3 システムによる利用率
システムによる負荷の推移も、表-1の集計上はほぼこれまでと同様であったが、図-2に見るように、バージョンアップ以降、利用実績の積算、課金統計やネットワーク・ファイルシステム・サーバ、インタラクティブ・ジョブの処理を担当している#4ノードのシステム負荷が著しく改善された。これはバージョンアップに伴って、ノード内を分割するリソースブロック機能の活用と、ERSバージョンアップに伴いERSサーバ機能を外部化したことによる。最後に、これまでと同様、メモリ待ちによるプロセッサ時間の浪費はほとんどみられなかった。これは、引き続き、本システムがベクトル機として適切に運用および利用されていることを示している。
| MFLOPS (前年度比) |
平均ベクトル長 (前年度比) |
ベクトル化率 % (前年度比) |
|||||
| 2001年度 | sx50 | 44,833.54 | 332.92 | 94.44 | |||
| sx51 | 43,041.79 | 340.51 | 94.13 | ||||
| sx52 | 33,676.27 | 317.59 | 93.94 | ||||
| sx53 | 38,988.50 | 316.65 | 93.97 | ||||
| sx54 | 35,402.69 | 276.13 | 97.80 | ||||
| sx55 | 40,867.66 | 318.55 | 93.91 | ||||
| 全体 | 236,810.45 | 317.06 | 94.70 | ||||
| 2002年度 | sx50 | 32,425.16 (0.72) | 337.56 (1.01) | 95.08 (1.01) | |||
| sx51 | 26,797.54 (0.62) | 336.66 (0.99) | 96.28 (1.02) | ||||
| sx52 | 27,658.18 (0.82) | 306.67 (0.97) | 97.08 (1.03) | ||||
| sx53 | 28,688.94 (0.74) | 302.98 (0.96) | 96.24 (1.02) | ||||
| sx54 | 25,295.58 (0.71) | 278.05 (1.01) | 98.17 (1.00) | ||||
| sx55 | 34,461.94 (0.84) | 326.39 (1.02) | 95.89 (1.02) | ||||
| 全体 | 175,327.34 (0.74) | 314.72 (0.99) | 96.46 (1.02) | ||||
| 2003年度 | sx50 | 19,092.60 (0.59) | 302.33 (0.90) | 91.37 (0.96) | |||
| sx51 | 22,996.02 (0.86) | 301.66 (0.90) | 89.74 (0.93) | ||||
| sx52 | 26,665.77 (0.96) | 298.63 (0.97) | 93.69 (0.97) | ||||
| sx53 | 23,451.23 (0.82) | 290.05 (0.96) | 93.75 (0.97) | ||||
| sx54 | 30,016.08 (1.19) | 309.28 (1.11) | 96.28 (0.98) | ||||
| sx55 | 26,615.27 (0.77) | 312.45 (0.96) | 92.75 (0.97) | ||||
| 全体 | 148,836.97 (0.85) | 302.40 (0.96) | 92.93 (0.96) | ||||
2 2003年度の演算効率の推移
図-3にシステム全体の演算効率の推移を、図-4にノード毎の演算効率の推移を示す。グラフの集計期間は2001年1月から2004年3月末までである。表-2は、それぞれの値を年度毎に集計したものである。昨年度に引き続いて、単位時間当たりに処理している演算量、いわゆるFLOPS値が減少傾向にある。2001年度は、通年で平均しても236GFLOPSの処理をこなしていた。これはピーク性能960GFLOPSの25%に相当し、共同利用施設に設置されているハイパフォーマンス・コンピュータ・システムとしては非常に高い割合であると高く評価された。しかし、2002年度は、前年度比では26%減少し、175GFLOPSとピーク性能比18%まで落ち込んでいる。2003年度は更に前年度比15%減少し、ピーク性能比16%まで落ち込んだ。これでも依然高い実効性能で利用されているとも評価できるが、2001年度の実績があるだけに、手放しでは褒められない。
まず、ユーザ・プログラムのパフォーマンス・チューニングの指標となるベクトル化率や平均ベクトル長の推移を観察すると、一昨年および昨年度と本年度も大きな差はみられない。平均ベクトル長は317、314から302へと僅かに減少しているが、それが即演算効率に直結するような有意な差とは考えにくい。ベクトル化率は94.7%、96.5%から92.9%にやはり微減している。
これらの数値の低下は特に#0、#1ノードで目立つが、これは前章でも触れたように、32並列ジョブが2ヶ月近く占有し、そのジョブの効率が上がらなかった事による影響が大きい。当該ジョブは、非常に大容量のメモリを参照し、必然的に大規模なI/O処理を伴った。また、実行が長時間に及ぶことから、定期的にチェックポイントを採取し、予期せぬシステム障害によって実行経過が失われることを予防した。これらの要因で、演算効率が上がらなかったことは不可避であった。ちなみに、当該ジョブの並列実行率は97%前後と推定されるが、16並列では70%の利用効率が得られるが、32並列で実行すると50%まで効率が低下するものである。
今回の更新作業がユーザ・プログラムの効率向上に短絡的に結びつかなかったことをうけ、ジョブ・クラスの規定値の見直しを進めている。これまでは、アカウント処理の際に換算係数を設定し高並列化を促進してきたが、大規模メモリを参照する必要のないプログラムに関しては、演算効率の高い低並列のジョブ・クラスへ誘導するように促していく必要があると考えており、ひいてはジョブ毎のターン・アラウンド・タイムを向上に繋がると期待している。
3 おわりに
フェアシェア定額制度を導入し3年余が経過した。昨年からは、東北大学にてSX-7の運用が開始され、我々センターとしても、厳しい運用を迫られることとなっている。幸いにも、東北大学のシステム稼働後もジョブ投入数が減少することもなく、これまで同様の利用率で稼働している。本年度7月には、初めての大がかりなシステム構成変更を行った。オペレーティング・システムのバージョンアップを行なうとともに、フェアシェア定額制度運用を支える基盤ソフトウェアであるERSのバージョンアップとキュー構成の変更も行なった。これによりシステム運用上の統計的には改善されたが、個々のユーザ・プログラムの効率向上に対して効果があるものではなかったことが判明した。後者に関しては、ジョブ・クラスの規定値の見直しによって効率改善を図り、システム全体のスループットを上げることにより個々のジョブのターン・アラウンド・タイムが向上するように図りたい。
さて、本システムは、Linpackベンチマークにてベクトル型スーパーコンピュータとしては初めて1TFLOPSを超える実効性能 (1,192GFLOPS) を達成した画期的なシステムであるが、このシステムをあと3年維持することは、利用者各位の研究活動に遅滞を招かないだろうか。
一昨年、本システムと同様のアーキテクチャを持つ地球シミュレータ (http://www.es.jamstec.go.jp/) が稼働し、Linpackベンチマークにて35.86TFLOPSというこの分野での先進性を自認してきた米国にとってスプートニクショック以来の技術的屈辱と例えられる飛び抜けたベンチマーク性能を達成したことで、絶対性能としては随分見劣りするものとなっている(地球シミュレータは、実シミュレーションでも10TFLOPSを越える性能を実現している)。
2003年11月付けの“TOP500 Supercomputer List” (http://www.top500.org/) において、本システムの位置づけは、導入年の12位、昨年の34位からさらに88位にまで後退したものの、100位以内に踏みとどまり面目を保った。国内に目を向けると、圧倒的実効性能で一位を保持した地球シミュレータ、宇宙航空研究開発機構(旧、航空宇宙技術研究所)の富士通製HPC2500、東京大学の日立製SR8000、核融合科学研究所のNEC SX-7が本システムの上位に位置付けられているのみで(東北大学のSX-7は、分散運用を前提としているためか登録されていない)、このリストから鑑みれば依然として競争力を保っていることになる。
一方で、このTOP500リストの形骸化の指摘は久しいが、本年、バージニア工科大のPowerMac G5を1,100台クラスタ結合したシステムが、米国の数ある国家プロジェクトを退けて3位にランクインしたことで、関係者のほとんどがこのリストと現実の演算性能との乖離に目を覚ましたことを特筆しておこう。国内でも産業技術総合研究所・グリッド研究センターにて“AISTスーパクラスタ”や、理化学研究所・情報基盤センターでは“スーパーコンバインドクラスタ”など、Linpackベンチマークにて10TFLOPS以上の実効性能を達成可能なPCクラスタ・システムが稼働を開始しようとている(後者はベクトル型スーパーコンピュータSX-7とのハイブリッド・システムである)。
しかし、本稿でも繰り返し指摘しているように、高性能演算システムを効率的に運用するためには独特のノウハウが必要であり、さらにその演算効率まで含めて検証を行うと、性能達成が容易といわれるベクトル型スーパーコンピュータをもってしても、効率的運用はきわめて困難である。
また、低コストで高性能と持て囃されてきたPCクラスタも技術的転換点を迎えていることを認識すべきであろう。インテルがPentium4に採用されていた“NetBurst”アーキテクチャの開発計画をすべてキャンセルしたとの一部報道は、PCクラスタを推進してきたグループに大きな衝撃をもって迎えられている。このような性能チューニング技術の白紙化は、特に独特の性能向上ノウハウを必要とするPCクラスタにおいては研究活動に大きく支障をきたすものである。また、プロセッサ製造プロセスの微細化に伴うリーク電流の増大は、PCクラスタの運用コストに著しい悪影響を与えている。実際、同程度の演算効率を持つベクトル型スーパーコンピュータとPCクラスタでは、ほぼ同じ程度の電力を消費するというシミュレーション結果も報告されている。
来年度からは、次期システム検討委員会が組織され後継システムの調達手続きが始まる。教育研究機関に所属する研究者に供する共同利用システムとして、形骸化したTOP500リストに拘泥することなく、新たな指標を示すシステムを目指さなくてはならない。それと同時に、独立行政法人化後の共同利用システムのあり方の模索、特に民間利用への供し方も考慮されなくてはならないだろう。パソコンやワークステーションをクラスタ化、そしてグローバル・リソース化するグリッドウェアの開発整備も著しいが、教育研究機関が共同利用に供する程には熟成されていない。また、適用可能な研究分野も非常に限られている。なにより、利用者が容易に性能を引き出すまでにはこなれていない。本システムの運用実績とグリッドに対する研究成果を生かし、利用者にとって魅力ある後継システム選定に留まらず、新しい高性能大規模計算システム環境の提案を行なうことになろう。
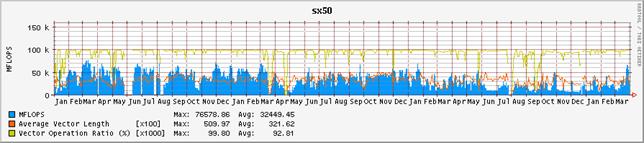
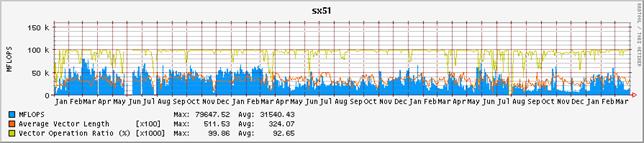
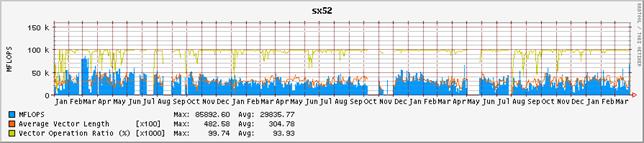
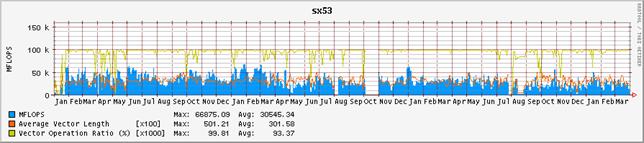
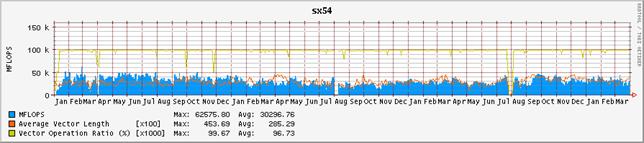
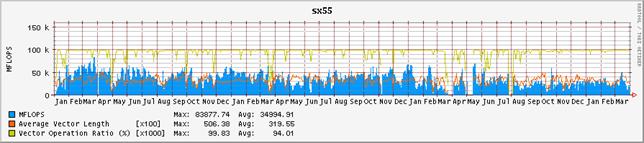
図-4:ノード毎の演算効率の推移(2001年1月から2004年3月末まで)